Machine Learning for your Grandma
The strawberry tale
We explain the very basics of ML with a story that draws parallels between human learning and machine learning.
One day, Harry decides it’s time to visit his grandmother in the retirement home. To surprise her, he decides he will buy the sweet strawberries that she likes. Laura, the saleswoman, sells strawberries in a way that Harry can pick and choose.

Harry was told by his grandmother that bright red strawberries are sweeter than pale ones. That is why he makes a simple rule: pick only the most vibrant strawberries. Harry checks the colour of the strawberries, chooses the bright red ones, pays and then goes to the retirement home to visit his grandmother.
Experience 1: Bright red strawberries are sweeter than pale strawberries
On the way to the retirement home, Harry tastes the strawberries and discovers that some are not as sweet as he thought. He concludes that when buying strawberries, more factors are involved than just the colour.
Harry notices that the larger and bright red strawberries are guaranteed to be sweet, while the smaller bright red ones are only half as likely to be sweet. Harry changes his rule and the next time he goes to buy strawberries, he will keep the adjusted rule in mind.
Experience 2: Small and bright red strawberries are only sweet half the time
A few weeks later Harry visits the market again and notices that Laura is out of town. This time, he decides to buy from another store, that cultivates strawberries in another part of the country.
The rule that Harry learned (large bright red strawberries are the sweetest) no longer applies to this vendor. Harry has to start from scratch and gets the opportunity to taste all kinds of strawberries in the supplier’s range. He learns that the small, light red ones are actually the sweetest of them all.
Experience 3: Small light red strawberries are the sweetest of them all
Harry’s niece comes to visit him and he decides to treat her to some strawberries. Harry tells her that these kinds of strawberries are the sweetest, to which she answers: “I only like juicy strawberries, not a fan of the sweet ones.” Harry’s rules do not seem to work for everyone, he again tries many types of strawberries and concludes that the softer ones are the juiciest.
Experience 4: Soft strawberries are the juiciest
Harry is offered a job on the other side of the world. He migrates and goes to the local market to buy some strawberries. He notes that the strawberries taste surprisingly different than in his own country. In this country, the green strawberries are tastier than the red ones.
Experience 5: Green strawberries are tastier than red ones
On the other side of the world, Harry meets his future wife who does not like strawberries but apples. Harry is now buying apples instead of strawberries. All his accumulated knowledge about strawberries is now worthless. Harry now focuses on the correlation between the physical characteristics and taste of different types of apples.
Experience 6: Harry no longer needs strawberries
Human programming
Suppose Harry is asked to write a computer program on how to select a specific type of strawberry. He will be able to write down the following rules to choose strawberries:
- If red, large and sold by Laura: strawberry is sweet
- If soft: strawberry is juicy
However every time Harry makes a new observation while tasting strawberries on the market, he has to manually change his list of rules. He should understand all the details of the factors involved in the quality of the strawberries. Writing precise rules for all species of strawberries by hand can be very difficult for Harry. This takes a lot of research and time. Machine learning could be very useful for this problem.
Machine Learning
Machine learning is roughly defined as an application that offers computers the ability to autonomously learn and improve based on experiences, observations and pattern analysis of a given dataset without explicit programming. The goal of machine learning is to constantly adapt to new data and discover new patterns or rules in it.
When writing a program, we used to code a clear set of instructions for the computer to follow. With machine learning, we use a dataset from which the system learns patterns and correlations by itself. The patterns that are found are saved in a mathematical model.
Learning process
The machine learning process consists of a training and a testing phase.
Training Phase
Harry randomly chooses some strawberries from the market. He makes note of all the properties of each strawberry such as color, shape, size and origin, as well as what you can only know after tasting: sweetness and juiciness. Harry feeds the machine learning algorithm with the collected data, after which the algorithm learns to find the correlation between the physical characteristics and the taste properties of a strawberry.
Testing Phase
Next time Harry goes shopping, he measures the characteristics of the new strawberries (test data) and enters this information into the machine learning algorithm which will tell him if a particular strawberry is sweet and/or juicy. The algorithm uses its own rules, similarly to the ones that Harry had written. Finally Harry can buy strawberries with confidence, knowing they will taste good.
The more, the better
After all, who doesn’t like eating strawberries? Over time the algorithm will perform better as it receives more and more training data. If the model makes an incorrect prediction, the model will update its rules so that it is less likely to make similar mistakes in the future. The same algorithm can be used to train different models so that in addition to the taste of strawberries, we can do the same for apples, pears and bananas.
Types of Machine Learning
Broadly speaking there are three types of machine learning approaches: supervised, unsupervised and reinforcement learning.
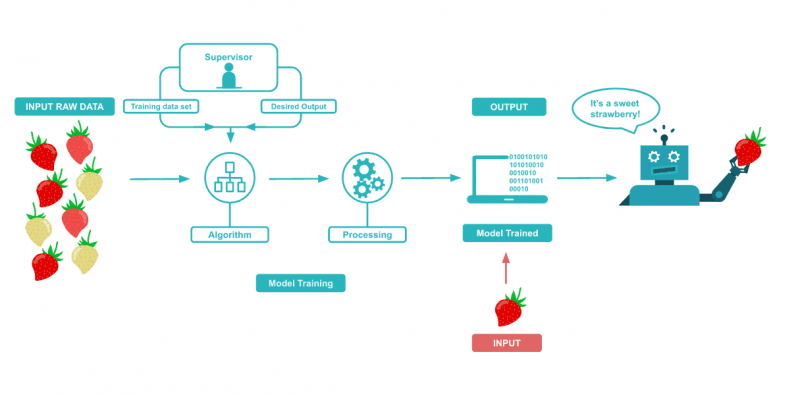
Supervised learning
Supervised learning considers a series of input variables (X) -such as strawberry size, color and weight- and an output variable (Y) -e.g. sweetness- where an algorithm is used to learn the assignment function from input to output.
Y = f (X)
The goal is to approximate this mapping function so well that when the model receives new input data (X), it can easily predict the output variable (Y) for that data.
Unsupervised learning
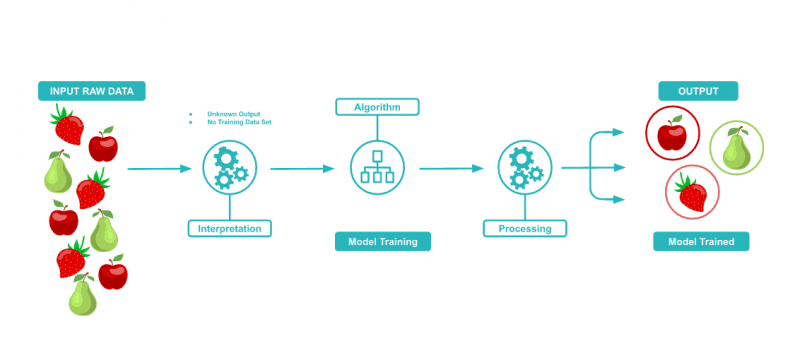
Unlike supervised learning, there is no teacher present in unsupervised learning. Algorithms just try to discover interesting patterns and groups in the data. Mathematically speaking, with unsupervised learning, only the input information (X) is available and no associated output.
The purpose of unsupervised learning is to model the underlying structure or distribution in the data to learn more about the data. If we were to give an unsupervised algorithm picture of different types of fruit it should still be able to discern between the types while it has never been told which pictures are of strawberries, apples or pears.
Reinforcement learning
Reinforcement Learning is much like training a dog. Unable to speak the same language as that cute puppy in the room. We, as the supervisor, need to use indirect communication via rewards and punishments to teach the pup. The principle of rewards and penalties means that for every decision the algorithm makes, it will either be rewarded or punished, so the algorithm will understand whether or not the decision was correct. This way the machine learns to make the right decisions to maximize the long-term reward.
In reinforcement learning, an agent is interacting with a simulated or real environment. The learning agent explores different actions and uses its knowledge of the environment to exploit actions to get rewarded.
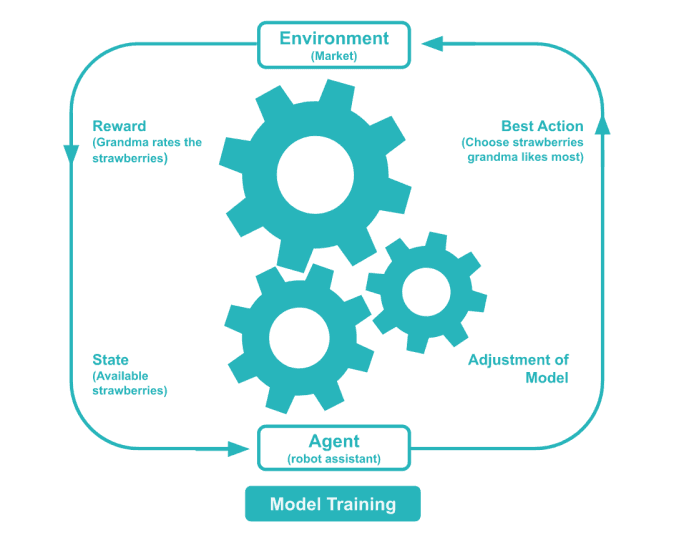
The environment rewards the agent for every correct action, which is the reinforcement signal. The end goal is to maximize the total reward. The agent is not told which action to take, but must instead discover which action yields the maximum reward.
Machine Learning and ML2Grow
Want to stop wasting your valuable time thinking about strawberries? Or your grandmother? Or are you just interested to apply machine learning in your business? Contact us today to learn how we can help you benefit!