Getting Nostalgic with Recurrent Neural Networks
What are recurrent neural networks?
RNNs are neural networks that have a memory. They keep track of what they have seen and use this to support their classification or regression output for a certain element in a series. When modeling a sentence, an RNN would see the letters GRANN and then predict a Y as the next letter because the network remembers the context from the previous three letters. This contrasts with a simple neural network that always would predict E (the most common letter in the English language) because it could not remember the previous letters.
Recurrent Neural Networks can largely, but not completely, resolve predictive sequences. These days, we expect computers to be so good to rewrite e.g. the Game of Thrones final season. RNNs excel when it comes to short contexts, but to be able to build and remember a Game of Thrones season, models are needed to understand and remember the context behind the sequences. Just like a human brain would. However, this is not possible with a simple recurrent neural network.

Why not?
RNNs are excellent for short sequences with low dependencies. The network can be applied to predict the next word in the following sentence:
“The color of a strawberry is …”
RNNs appear to be quite effective for predicting the next word in this sentence. This is because this problem has nothing to do with the context of the sentence. Recurrent Neural Networks do not have to remember what was said before or what its meaning was. The only thing the network needs to know is that strawberries are red in most cases. So the prediction would be:
“The color of a strawberry is red”
However, simple RNNs fail to understand the context behind an input. Things that were said a long time ago cannot be remembered to make predictions because of the huge amount of irrelevant data. The main cause is the vanishing gradient problem. This problem arises when training normal neural networks with backpropagation.
Backpropagation involves going through the network recursively to update the weights of each layer. To update the weights, a gradient of the cost function is obtained and the gradients in the layers are continuously multiplied using a chain rule. This can cause two problems.
When the gradients are greater than one, the updated values become so large that they can be used for optimization. These are called exploding gradients. But this is not a serious problem because we can clip the range that the gradients cannot exceed.
The real problem arises when the gradients are less than one. Multiplying values less than one results in even smaller values. After a few steps, we cannot update the weights because there is no significant difference in the outcome. This is called vanishing gradients where the back-propagation effect cannot go far enough to reach the early stage of layers. This makes training the layers difficult and makes the network unreliable. Recent new activation functions such as RELU have alleviated this problem.

A similar process is also observed in RNN’s. The network remembers things only for a limited period. Information that is needed after a short time is reproducible. If a lot of words are used as input, the information will be lost somewhere. Long Short-Term Memory Networks (LSTM) are used to attempt to solve this problem.
LSTM networks
LSTMs are a somewhat modified version of RNNs. They make small changes to the information through multiplications and additions. With LSTMs, the information flows through a mechanism called cell status. This way, LSTMs can selectively remember or forget things. The information in a certain cell status has three different dependencies.
This can be clarified based on an example. When predicting the stock price, the output will depend on:
- The trend of the past days
- The price on the previous day
- The factors that can influence the price of the stock for today. This can be a new corporate policy that is widely criticized, or a decline in company profits, or perhaps an unexpected change in the company’s senior leadership.
These dependencies can be generalized for each problem:
- The previous cell status (the information that was present in the reminder after the previous time step)
- The previous hidden state (this is the same as the previous cell’s output)
- The input at the current time step (the new information is entered at that time)
LSTMs can be compared with conveyor belts. In the industry, they are used to move products and raw materials through different processes. Just like conveyor belts, LSTMs also use this mechanism to move information. While the information is on the conveyor belt, information can be added, modified or deleted as it flows through the different layers of the network. Thanks to this feature of LSTMs, information can be slightly modified, selectively forgotten and remembered.
A similar process is also observed in RNN’s. The network remembers things only for a limited period. Information that is needed after a short time is reproducible. If a lot of words are used as input, the information will be lost somewhere. Long Short-Term Memory Networks (LSTM) is used to attempt to solve this problem.
A typical LSTM network consists of different memory blocks called cells. There are two states that go to the next cell; the cell state and the hidden state. The memory blocks are responsible for remembering things and manipulations for this memory are done through three important mechanisms, called gates.
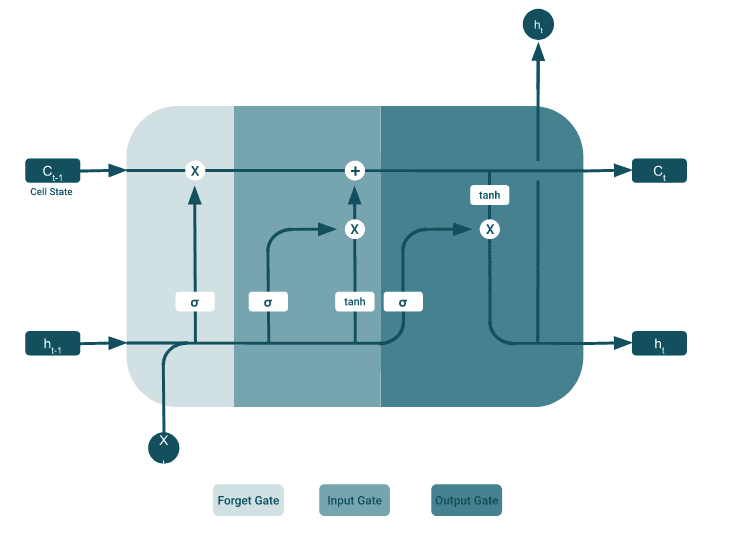
The forget gate
The forget gate determines which information must be forgotten and which must be remembered. Information from the hidden state of the previous cell and information from the current input is passed through the sigmoid function. This function outputs a vector with values from 0 to 1 that correspond to each value in the cell state.
When a “0” is executed in the cell status for a certain value, this means that the forget gate wants the cell state to completely forget the information. Likewise, a ‘1’ means that the forget gate wants to remember that whole piece of information. This vector output of e.g a sigmoid function is multiplied by the cell status. This can be clarified with the following sentence:
“Sophie goes to the bathroom to take a bath. Lynn was working in … ”
When the LSTM tries to predict the word in the second sentence, the network will never need the first sentence to predict the word. This is because there is a change in subject, unnecessary information that would otherwise be passed on in RNN.
The input gate
The input gate is used to update the cell state. Just like with the forget gate, the hidden state of the previous cell and the current input is passed on to the sigmoid function. This will decide which values are updated by transforming the values between 0 and 1. Values close to zero are unimportant, where values close to 1 are important.
The cell state
A new cell state can be obtained by pointwise multiplying the current cell state with the forget vector. This gives the possibility to delete values if they are multiplied by values in the vicinity of zero. Afterwards, the output from the input gate is used to update the cell state to a new cell state via a pointwise addition.
The output gate
The output gate determines what the next hidden state should be. The output from the output gate is the hidden state. The new cell state and the new hidden state are transferred to the next time step.
What about GRU’s?
GRUs are a newer generation of RNNs and comparable to LSTMs. GRUs do not use a cell state, but a hidden state to transfer information. The network only has two ports: the reset gate and the update gate.The operation of the update gate is similar to the forget and input gate of an LSTM network. It determines which information must be removed and which new information must be added. The reset gate is used to determine how much past information should be forgotten.GRUs have fewer operations; therefore they are a bit faster to train than LSTMs. However, there is no clear winner and engineers usually try both to determine which one works best for their use.
Don’t forget
The concept behind RNNs and LSTMS seem pretty intimidating, but walking through it step by step made it hopefully more approachable. RNNs lack when learning from long term dependencies, where LSTMs outperforms. LSTM’s ability to forget, remember and update the information pushes it one step ahead of RNNs.
More info? Do contact us!